📖 MetaCloak_ Preventing Unauthorized Subject-driven Text-to-image Diffusion-based Synthesis via Meta-learning
Cite as: CVPR
Submitted on 2024
Yixin Liu, Chenrui Fan, Yutong Dai, Xun Chen, Pan Zhou, Lichao Sun
Abstract
Problem: Text-to-image models can create harmful content, risking individual safety. Existing methods aim to make images “unlearnable” but have limitations.
Limitations: Current methods are sub-optimal due to manual heuristics in complex optimization. They lack robustness against simple transformations like Gaussian filtering.
Solution:
MetaCloak enhances image resistance to transformations (flipping, cropping, compression) by using surrogate diffusion models to craft transferable perturbations and a denoising-error maximization loss for better robustness.
Introduction
Some data protections are fragile and demonstrate limited robustness against minor data transformations such as filtering.
Design MetaCloak, a more effective and robust data protection scheme that can prevent unauthorized subject-driven text-to-image diffusion-based synthesis under data transformation.

Problem Statement
The user’s (image protector’s) objective is to protect their image set Xc.
User injects small perturbations into images x ∈ Xc to craft a poisoned image set Xp.
The model trainers will collect and use Xp to fine-tune a text-to-image generator x̂θ, in order to obtain the optimal parameters θ*.
The overall goal:
(4) Maximize Perturbation: Find the optimal perturbation to the images can effectively confuse or hide the true content of the images, thereby preventing the generative model from correctly identifying these images.
(5) Minimize Image Recognition Capability: Adjust the parameters of the generative model, such that the model’s ability to recognize the perturbed images is minimized, allowing the model to fail to learn or identify the original image content.
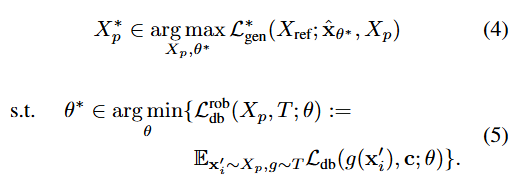
Method
Optimizing the proxy model parameters θ̃.
Minimizing the model’s recognition capability on the protected image Xp.
Using SGD -> The updated protected image Xp should be as visually close to the original image X0p as possible, while also maximizing the reduction in the generative model’s recognition capability.

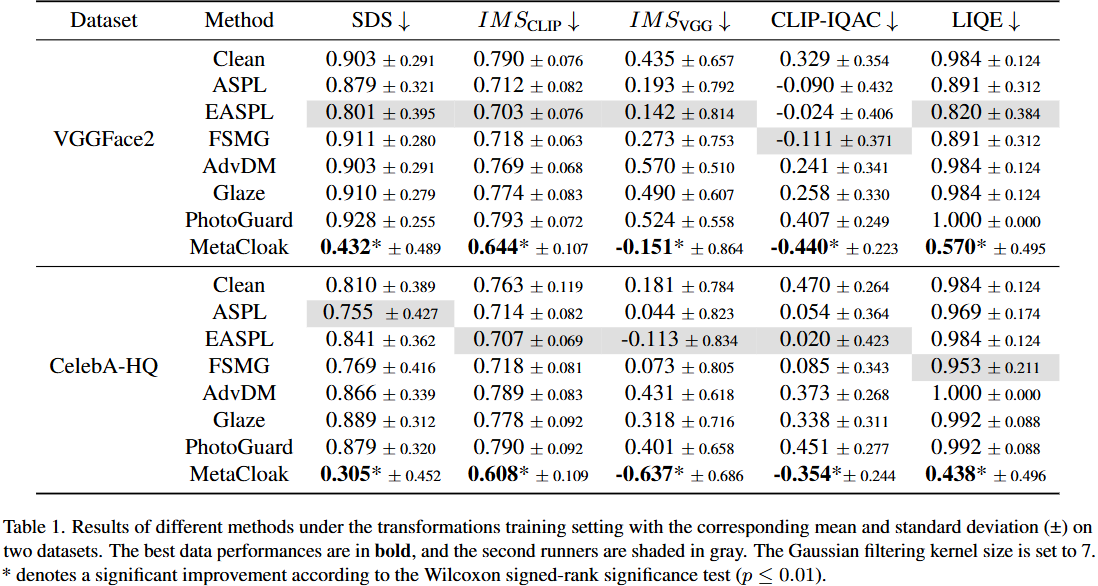
Results

Results