📖 Pen+CapAlign
Papers
- CapAlign: Improving Cross Modal Alignment via Informative Captioning for Harmful Meme Detection
Cite as ArXiv:2411.07527
Submitted on 2025/05
REF: https://arxiv.org/abs/2411.07527
- PEN: Prompt-enhanced Network for Hateful Meme Classification
Cite as ACM Web Conference 2024
Submitted on 2024/05
REF: https://dl.acm.org/doi/10.1145/3589334.3648146
Problem
Papers includes content for demonstration purposes that some readers may find disturbing.
Introduction (Hateful meme classification)
Stage 1: 早期的多模態融合 (Alignment and Fusion)
迷因包含「圖片」和「文字」兩種模態,所以模型必須同時理解這兩者。
-> Paper: Hateful Meme Challenge, Vilio
Stage 2: 導入外部知識 (External Knowledge)
光靠圖片和文字還不夠。很多仇恨言論是隱晦的,需要複雜的推理和背景知識才能看懂 。
-> Paper: DisMultiHate, MultiModal Learning
Stage 3: 模態轉換 (Modality Transformation)
不直接處理圖片,而是將多模態任務轉變為純文字任務 。當時的多模態模型(如 VilBERT、VisualBERT )雖然能同時處理圖文,但它們在訓練時沒有被賦予這些龐大且隱晦的文化、宗教、社會背景知識。
-> Paper: PromptHate (2022), Pro-Cap (2023)
Challenges & Solutions
- Challenges
Previous approaches using encoding and fusion of multiple modalities often challenged by the gap between the modalities.
Transforming multiple modalities into a single one(texture) also suffer from the quality of the image captions.
- Solutions
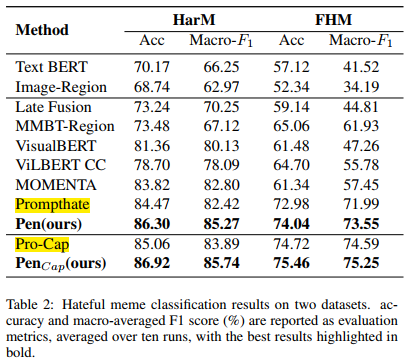
A stronger image caption generator utilizing LLM and larger visual language models.
An aligner (CapAlign) to address the misalignment of the modalities.
Paper 1: CapAlign
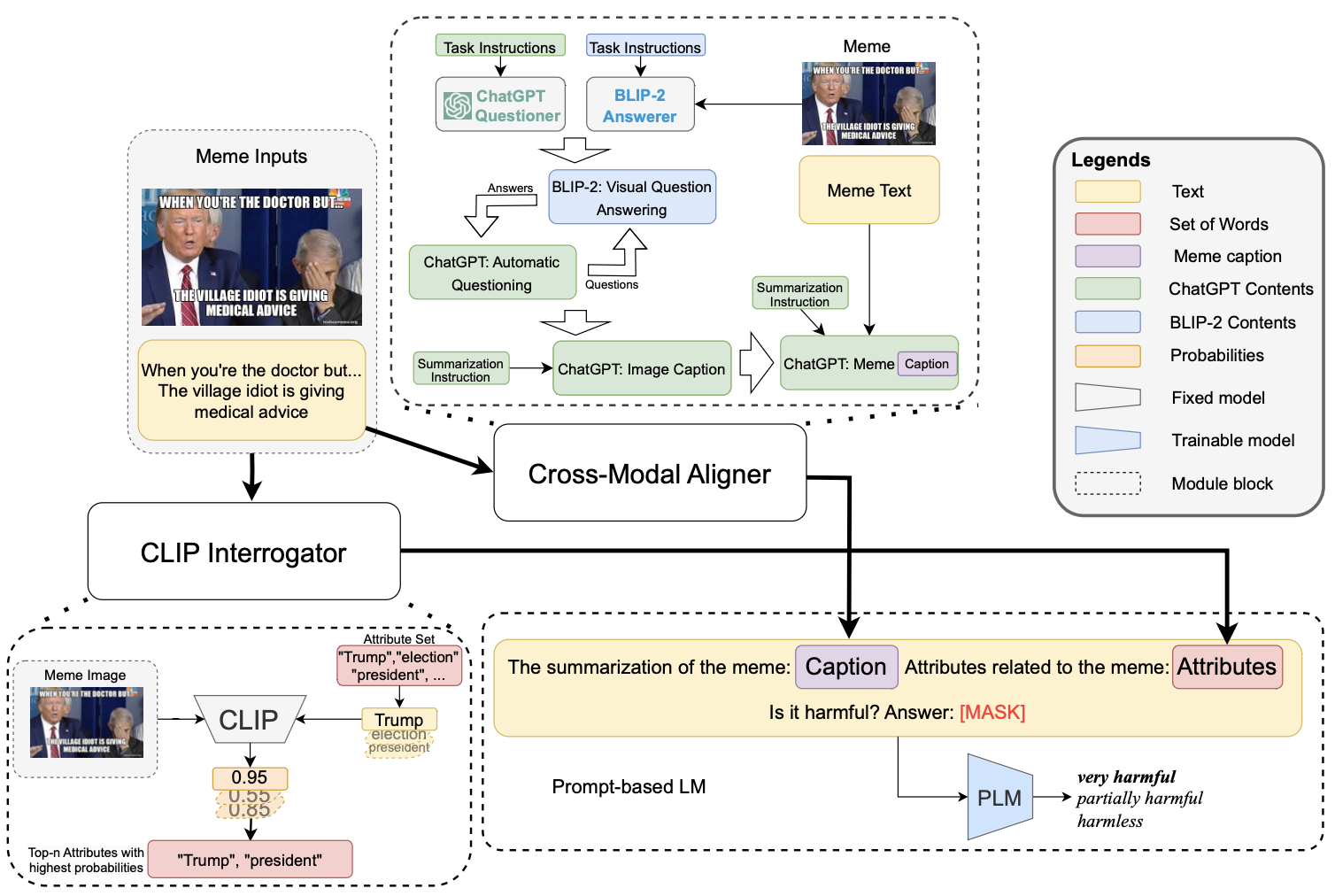
Results
Paper 2:PEN
Problems & Improvements
Problem 1: 僅靠「資料處理」,缺乏「特徵感知」
Prompthate / Pro-Cap 做法:僅在資料處理階段將迷因轉為文字,並排好「範例」(Demonstrations)。
模型缺乏專門的架構去「感知」和「比較」待分類迷因與範例之間的特徵關聯。
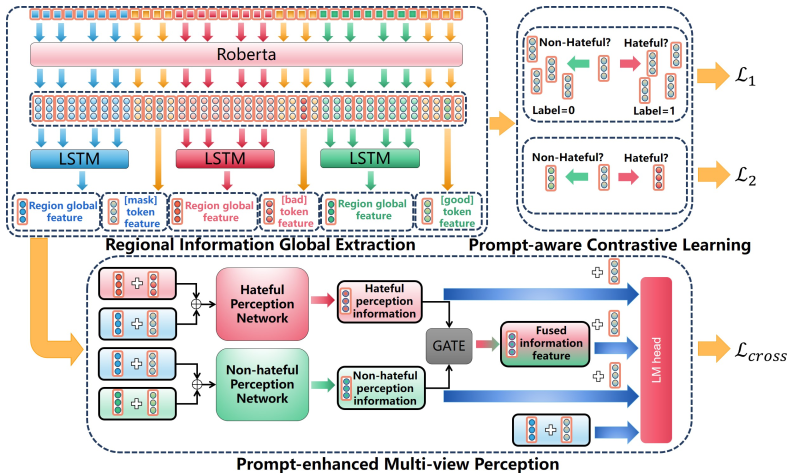
Improvement 1: PMP(Prompt-enhanced Multi-view Perception)
將提示擴展到特徵空間,建立 HPN / NHPN 網路主動去學習「待分類特徵」與「範例特徵」的關係。
Problem 2: 訓練目標單一,特徵邊界模糊
Prompthate / Pro-Cap 做法:僅依賴標準的「分類損失」(Cross-Entropy),目標是讓 [MASK] token 預測正確。
沒有顯式地 (explicitly) 強迫模型拉開「有毒」和「無害」樣本在特徵空間中的距離。
Improvement 2: PCL(Prompt-aware Contrastive Learning)
透過 L1 (類別導向) 和 L2 (提示導向) 兩個新損失,主動「雕塑」特徵空間,使同類更聚集、異類更分離。
Framework
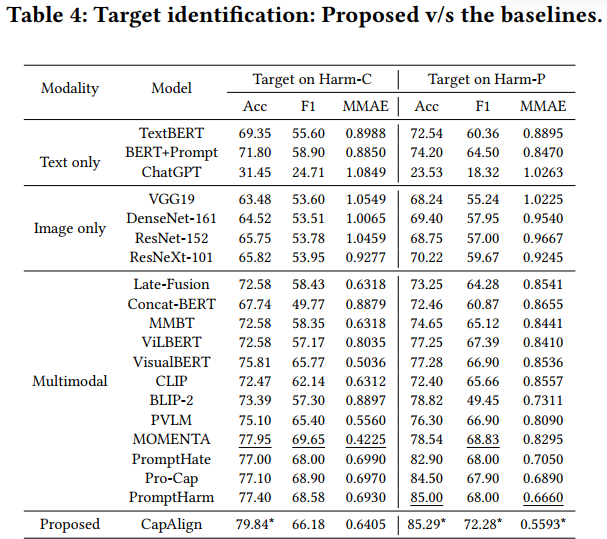
Results