📖 Progress+gpt4o-img-gen
Survey
Safety at Scale: A Comprehensive Survey of Large Model Safety
Xingjun Ma, Yifeng Gao, Yixu Wang, Ruofan Wang, Xin Wang, Ye Sun, …
ArXiv:2502.05206
Submitted on 2025/03
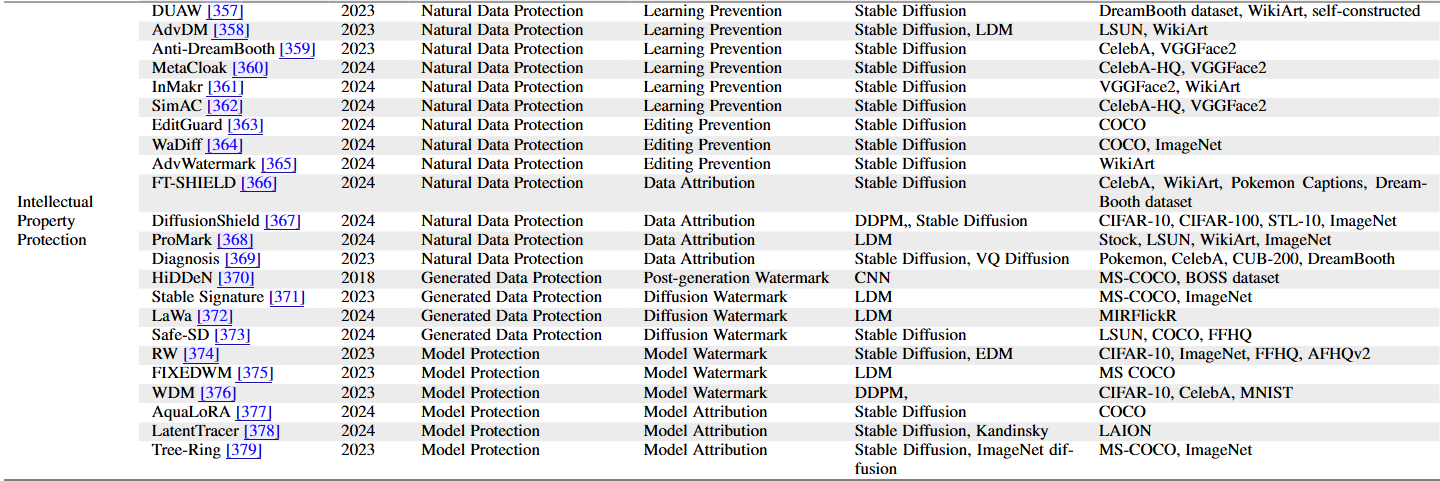
Intellectual Property Protection
Paper
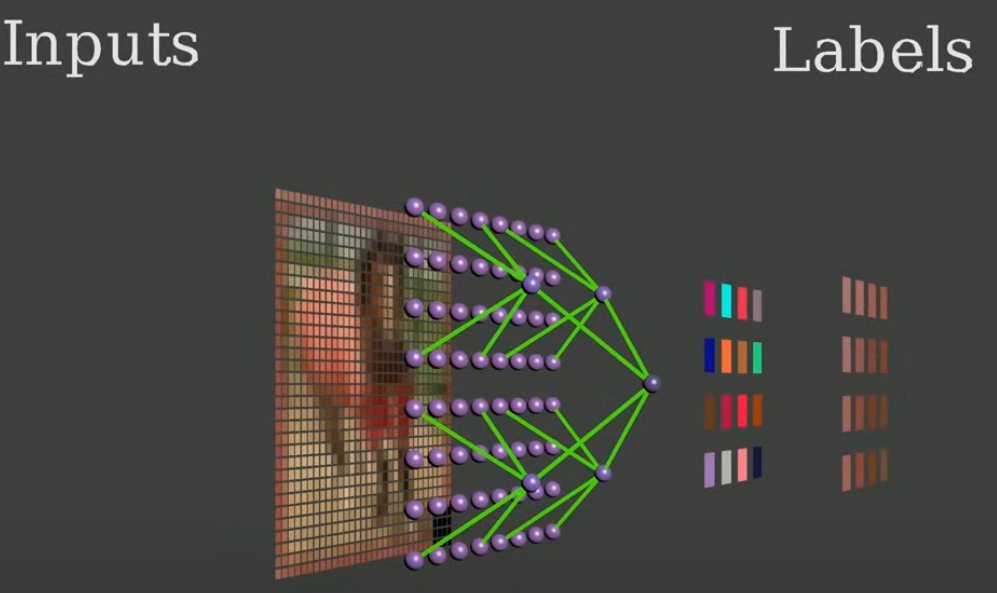
MetaCloak: Preventing Unauthorized Subject-driven Text-to-image Diffusion-based Synthesis via Meta-learning
Yixin Liu, Chenrui Fan, Yutong Dai, Xun Chen, Pan Zhou, Lichao Sun
2024 CVPR
Problem:
Text-to-image models can create harmful content, risking individual safety.
Existing methods aim to make images “unlearnable” but have limitations.
Proposed Solution: MetaCloak
Results:
- MetaCloak enhances image resistance to transformations (flipping, cropping, compression) by using surrogate diffusion models to craft transferable perturbations and a denoising-error maximization loss for better robustness.
Introduction
Some data protections are fragile and demonstrate limited robustness against minor data transformations such as filtering.
Design MetaCloak, a more effective and robust data protection scheme that can prevent unauthorized subject-driven text-to-image diffusion-based synthesis under data transformation.

Problem Statement
The user’s (image protector’s) objective is to protect their image set Xc.
User injects small perturbations into images x ∈ Xc to craft a poisoned image set Xp.
The model trainers will collect and use Xp to fine-tune a text-to-image generator x̂θ, in order to obtain the optimal parameters θ*.
The overall goal:
(4) Maximize Perturbation: Find the optimal perturbation to the images can effectively confuse or hide the true content of the images, thereby preventing the generative model from correctly identifying these images.
(5) Minimize Image Recognition Capability: Adjust the parameters of the generative model, such that the model’s ability to recognize the perturbed images is minimized, allowing the model to fail to learn or identify the original image content.
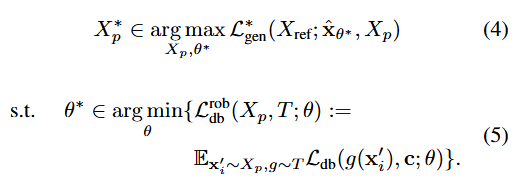
Method
Optimizing the proxy model parameters θ̃.
Minimizing the model’s recognition capability on the protected image Xp.
Using SGD → The updated protected image Xp should be as visually close to the original image X0p as possible, while also maximizing the reduction in the generative model’s recognition capability.

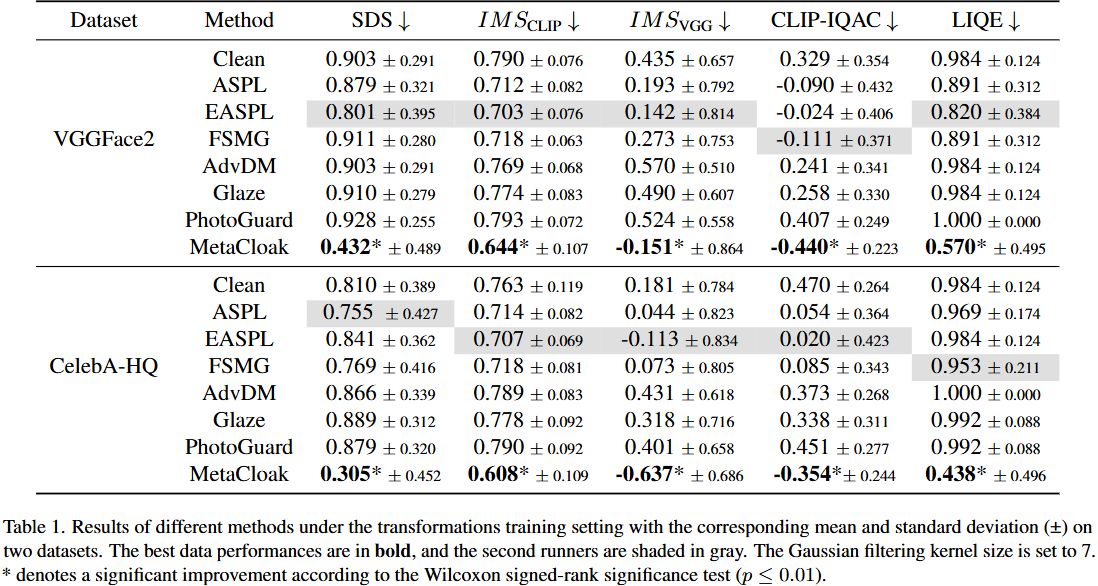
Results

Results
GPT-4o Image Generation
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, Zehuan Yuan
arXiv:2406.06525
2024/06
GPT-4o Image Generation
Technical Principles
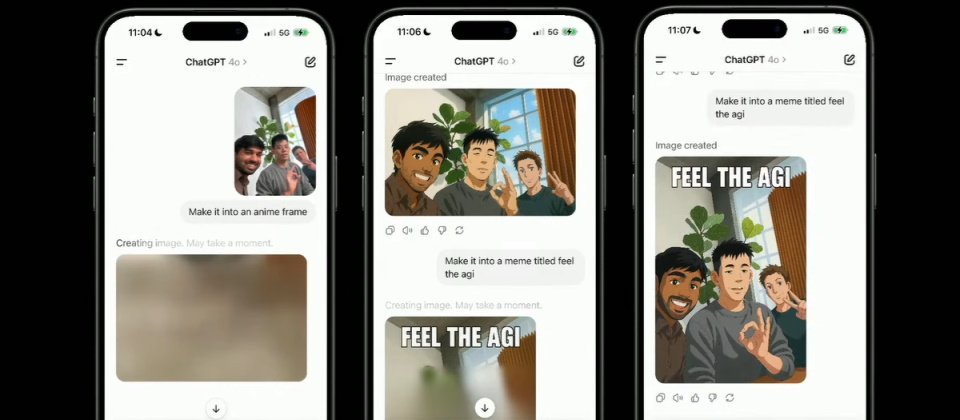
GPT-4o utilizes an autoregressive model, similar to how humans write, generating images step by step from the top-left corner to the bottom-right.
Compared to traditional diffusion models, this method significantly improves detail accuracy and text rendering quality, reducing random inconsistencies in images.
Model Training & Optimization
Training took over a year, as revealed by OpenAI research lead Gabriel Goh, with hundreds of human trainers refining details to enhance precision and AI comprehension.
Learning mechanism: The AI continuously improves by learning from human corrections, leading to better image quality and understanding.
Performance & Limitations
Slightly slower than DALL·E 3, but the improvement in image quality and knowledge integration makes the additional processing time worthwhile.
Comparison: Diffusion vs. Autoregressive
### | Aspect | Diffusion Model | Autoregressive Model |
| — | — | — |
| Working Principle | Starts with random noise, then applies multi-step denoising to generate a clear image | Step-by-step generation, |
| determines part of the final image with each step |
| Generation Process | Global approach, generating the entire image at once and refining details | Linear progression, constructing the image from top to bottom or left to right |
| Consistency & Stability | Since the process starts from random noise, maintaining consistency and stability is difficult | More controlled and stable, |
| improving semantic understanding |
| Examples | Stable Diffusion, DALL·E 2/3 | GPT-4o (image generation) |
| Advantages | Can create high-quality images, |
| stable and diverse | AR architecture can seamlessly integrate with LLMs, better for multimodal understanding, |
| accurately linking text and images |
| Disadvantages | Limited by random noise, |
| leading to inconsistent results | High computational cost, and image detail may be limited by token processing constraints |
GPT-4o’s Key Innovations
Balanced Speed & Quality → Optimized model structure ensures fast generation while maintaining high visual quality.
Consistency in Large Images → Advanced algorithms prevent detail inconsistencies, making images appear more natural.
Better Text-Image Alignment → Both text and images are vectorized into tokens, improving AI’s understanding and accuracy.
Possible Technical Explanations:
Token-Based Sketching → The model may first generate a rough sketch using tokens, followed by a refinement phase using a diffusion-like denoising process.
Chain-of-Thought (CoT) Style Refinement → The model could iteratively enhance the image step by step, similar to how CoT reasoning improves text generation.
Layered Input Processing → The model might generate a low-resolution draft first and then apply multiple processing steps to refine details and increase clarity.

參考
gpt-4o-img-gen:
https://x.com/dotey/status/1904684852982813022
https://www.facebook.com/photo/?fbid=10162841428450802&set=a.10150347633745802
https://www.threads.net/@prompt_case/post/DH0dmZcxtMt?xmt=AQGze7s1OXyuZ0F_Mh6jNpi8cGfsrCs3OcYjz-S6E8lYug
llama-gen:
https://www.threads.net/@shaochuanwang/post/DFBVLeTzeco