📖 SaRA
📖 SaRA
SaRA (High-Efficient Diffusion Model Fine-tuning with Progressive Sparse Low-Rank Adaptation)
Cite as: ICLR 2025
Submitted on 2025/04
Abstract
SaRA是一種用於預訓練擴散模型的高效微調方法。
SaRA旨在重新利用這些無效參數,使其重新變得有效,並使預訓練模型具備新的任務特定能力。
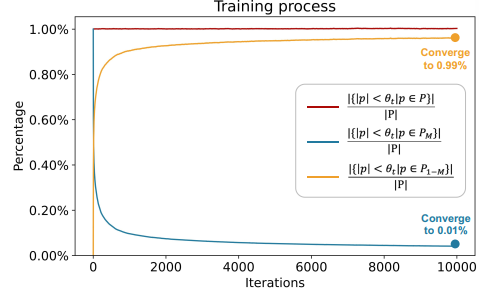
- 針對潛在有效參數的微調:SaRA首先識別預訓練模型中絕對值小於特定閾值 θt 的參數,這些被視為「暫時無效但潛在有效」的參數 。然後,它使用一個稀疏遮罩(sparse mask) M 來更新這些初始無效的參數 PM=P⊙M,同時凍結初始有效的參數 P⊙(1−M) 。 漸進式稀疏低階模型 Adapter
這種方法允許模型學習新知識,同時保留先前的知識 。 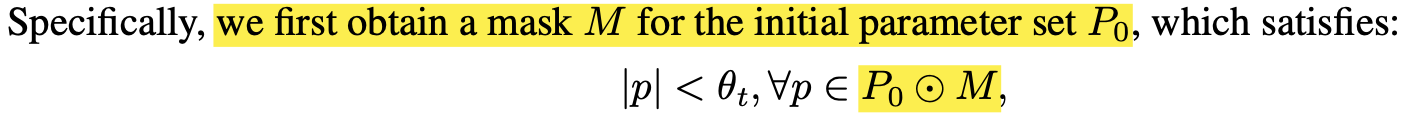
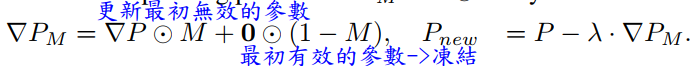
- 基於核範數的低秩約束:為了解決稀疏參數矩陣 PM 可能因高秩而導致過擬合的問題,SaRA引入了基於Nuclear Norm-based Low-Rank Constraint。這有助於限制學習到的稀疏矩陣的秩,減輕過擬合的風險 。
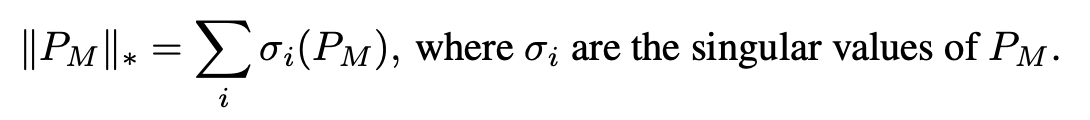
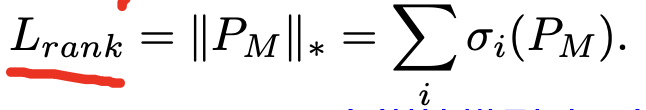
漸進式稀疏低階模型 Adapter
- 漸進式參數調整策略(Progressive Parameter Adjustment):為了確保微調過程中幾乎所有參數都得到充分利用,SaRA提出了一種漸進式參數調整策略 。 它在微調的早期階段之後,重新選擇那些仍低於預定義閾值的無效參數作為新的可訓練參數,並在後續階段重點優化這些參數 。
參數的無效性主要是由訓練過程的隨機性造成的,而非模型結構的固有問題。
初始時看似”無用”的小參數,在合理的訓練過程中大多數都能重新獲得效用
一些初始時”有用”的大參數,可能因為訓練過程的隨機性而暫時變得無效
這種現象表明,那些絕對值較小的參數並非結構性冗餘,而是具有潛在價值的
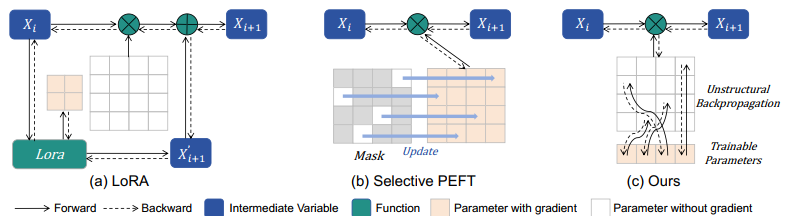
漸進式稀疏低階模型 Adapter
- 非結構化反向傳播:SaRA引入了一種新穎的非結構化反向傳播策略,以顯著降低微調過程中的記憶體成本 。與傳統方法需要保留整個參數矩陣的梯度不同,SaRA只為需要更新的選定子集參數保留梯度 。
這使得SaRA在記憶體效率上優於現有的PEFT方法 。
This post is licensed under CC BY 4.0 by the author.