📖 Towards Prompt-robust Face Privacy Protection via Adversarial Decoupling Augmentation Framework
Cite as: arXiv:2305.03980 [cs.CV]
Submitted on 2023/05
Ruijia Wu, Yuhang Wang, Huafeng Shi, Zhipeng Yu, Yichao Wu, Ding Liang
Abstract
The image-text fusion module is a vital component of text-to-image diffusion models, responsible for combining textual information with the image generation process.
Current privacy protection methods neglect this crucial fusion module, leading to unstable defense performance against different attacker prompts. This means they cannot effectively protect user privacy when faced with varying attack strategies.
The paper addresses a more challenging scenario where adversaries can utilize diverse prompts to fine-tune the text-to-image diffusion model, increasing the difficulty of privacy protection.
Abstract
Text-to-image diffusion models methods are unstable against different attacker prompts.
Methodology
Methodology
Vision-Adversarial Loss: L_VAL=॥x_rec - x_target॥^2
The goal is to bring the reconstructed image closer to the target image, distancing it from training samples.
→ Aims to improve generation quality, reduce overfitting, enhance model robustness, and facilitate effective feature learning.
Methodology
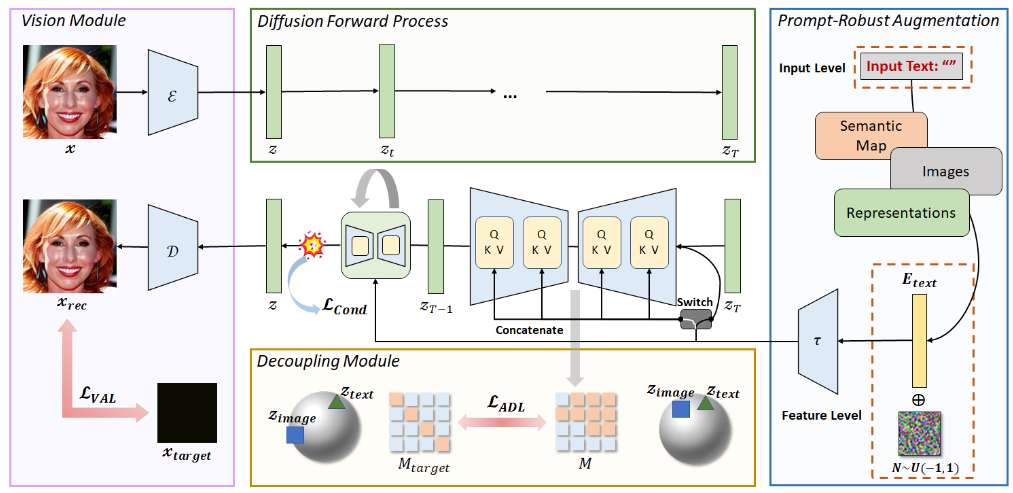
Prompt-Robust Augmentation (PRA):
text-to-image: “A cute cat sitting by the window.”
Overfitting problem: “a cat playing in the garden” -> fail
- At the Text Input Level
Reducing Overfitting
-> use two special characters:
Underscore: “A cute cat_sitting by the window.”
Empty: “A cute cat,”
- At the Text Feature Level
Diversifying Text
When generating adversarial perturbations, we can perform data augmentation on the text features.
Ex. “A cat in a tree”, “A cat in a tree, possibly with a dog.”
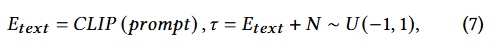
Methodology
Attention Decoupling Loss (ADL):
Focus on the attention matrix within the cross-attention mechanism to interfere with the image-text fusion process and prevent the network from establishing effective image-text mapping relationships.
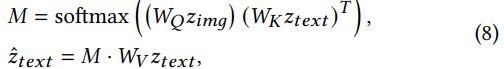
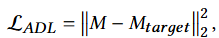
Methodology
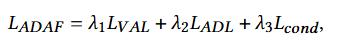
Experimental Setups
Datasets: Celeba-HQ, VGGFace2
Image Size: 512x512
Implementation Details: (Adversarial Attacks)
Method: Projected Gradient Descent (PGD)
Type: Untargeted attacks
Steps: 50
Step Size: 0.1
Budget: 8/255
Defense Evaluation: (Simulated Prompts for Adversarial Testing)
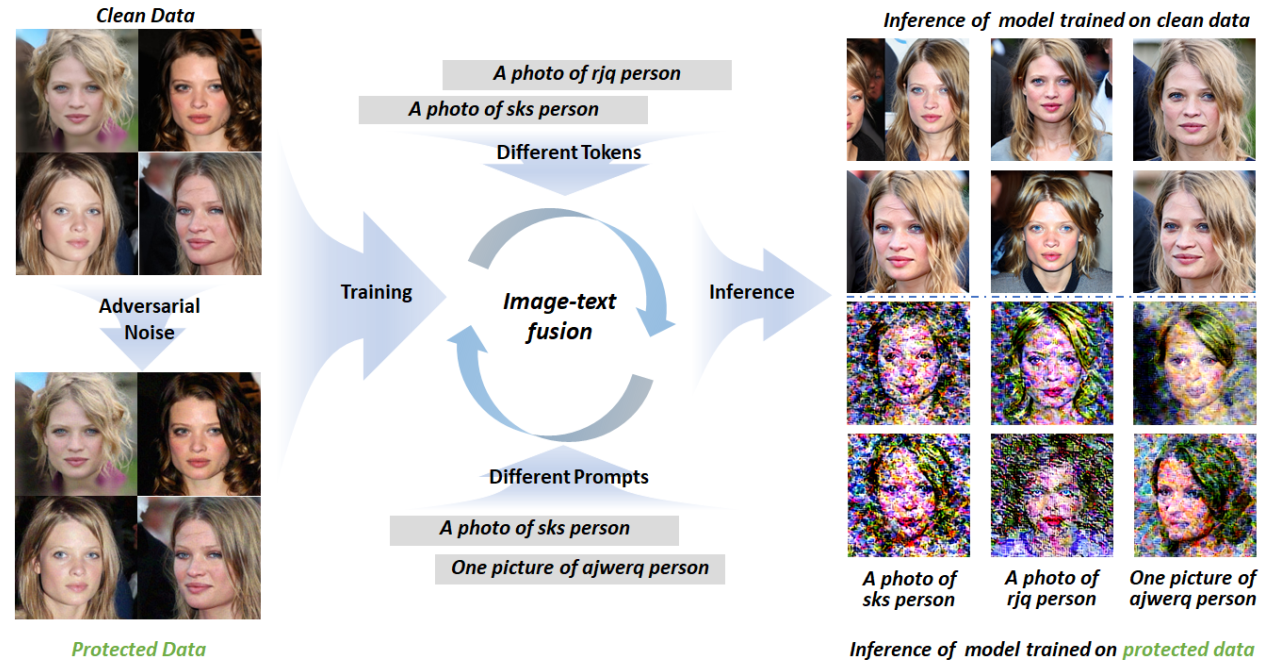
Token Level prompts: “a photo of ( S* )” where ( S* \in { sks, t@t, rjq, ajwerq } )
Prompt Level: “one picture of ajwerq person”
“a dslr portrait of rjq person”
Experiments
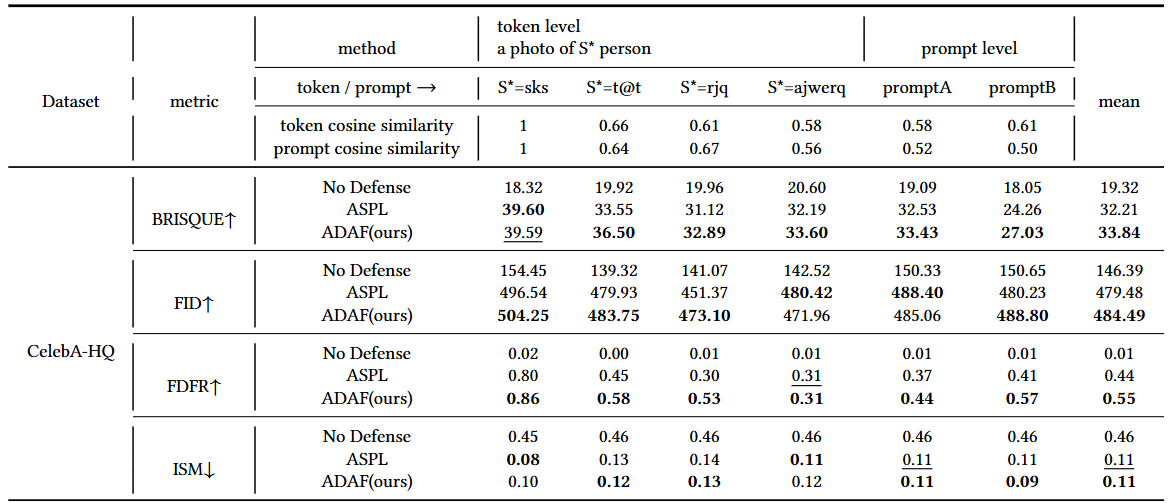
Experiments
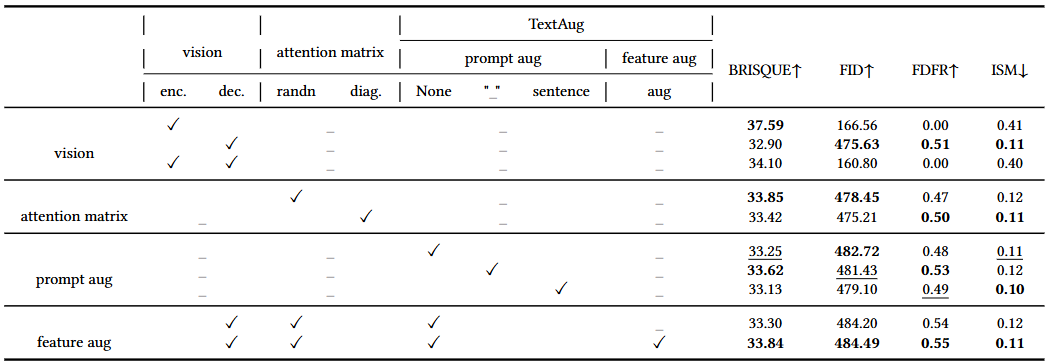
Experiments

Experiments

Conclusion
ADAF’s significance in enhancing privacy in generative models while paving the way for further advancements in this area.