📖 Training Diffusion Models with Federated Learning
Matthijs de Goede, Bart Cox, Jérémie Decouchant
Cite as: arXiv:2406.12575 [cs.LG]
Submitted on 18 Jun 2024
Abstract
Raising concerns about privacy, copyright, and data authority due to their lack of transparency regarding training data.
Propose a federated diffusion model scheme that enables the independent and collaborative training of diffusion models without exposing local data.
The approach adapts the Federated Averaging (FedAvg) algorithm to train a Denoising Diffusion Model (DDPM).
Communication Efficient Federated Diffusion
Federated Diffusion
Consider a cross-silo setting with a small set of K clients equipped with reasonable computing power and relatively large datasets Dk ∈ D.
Use Federated Averaging (FedAvg) algorithm to optimize the objective from Equation 9, as it has proven to be capable of training a wide variety of deep neural networks using relatively few rounds of communication between the federator and the clients.
relative size of dataset:
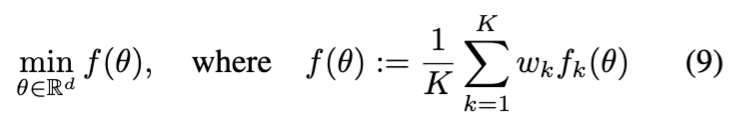
Comparison with three learnings…
1. Datacenter Distributed Learning:
A traditional machine learning approach where training occurs on a centralized dataset stored in a single data center or computing cluster. This setup is highly controlled and optimized for computational efficiency.
2. Cross-Silo Federated Learning:
Designed for training models across multiple independent organizations (e.g., hospitals, banks) that cannot share raw data due to privacy or regulatory constraints.
➡️ Cross-Silo Federated Learning is ideal for privacy-preserving collaboration between institutions.
3. Cross-Device Federated Learning
Designed for large-scale distributed training across numerous mobile or IoT devices, where each device contributes to training without sharing its data.
Cite as: Advances and open problems in federated learning arXiv:1912.04977 [cs.LG]
Communication Efficient Federated Diffusion
Training Rounds: For each round, each client updates their local model using mini-batch SGD on their dataset and returns the updated parameters to the federator.

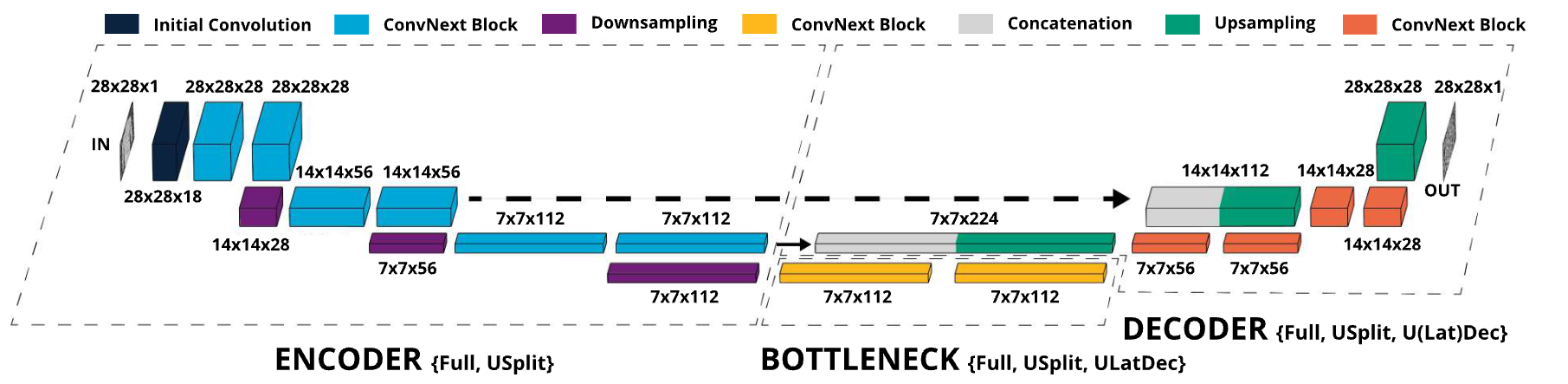
Structural characteristics of UNet and its application in FL
FULL Method: The federator sends the full parameter vector θ to each client and receives updated parametersθk.
USPLIT Method: Clients are assigned specific subsets of parameters for updates, paired randomly to report on the encoder and decoder.
UDEC Method: Collaboratively trains only the decoder parameters, allowing clients to use their locally trained encoder and bottleneck.
ULATDEC Method: Collaboratively trains both decoder and bottleneck parameters to unify feature selection.
Experimental Setup and Results
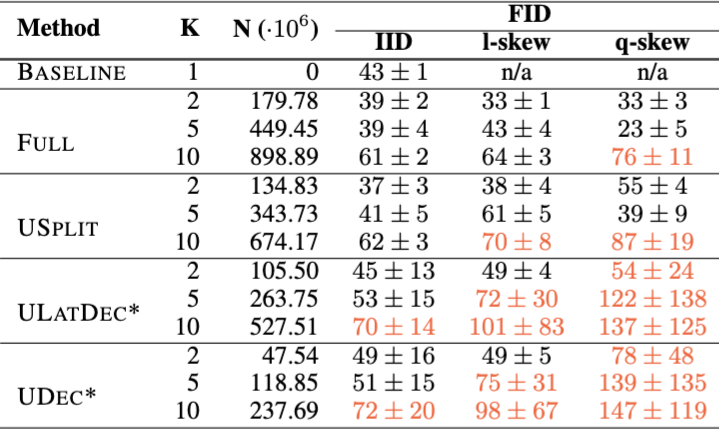
The lower the FID, the better the image quality.
Global test set only contained 10,000 images.
Measured the FIDs on client level, given that the federator only had access to partial models with ULATDEC and UDEC.
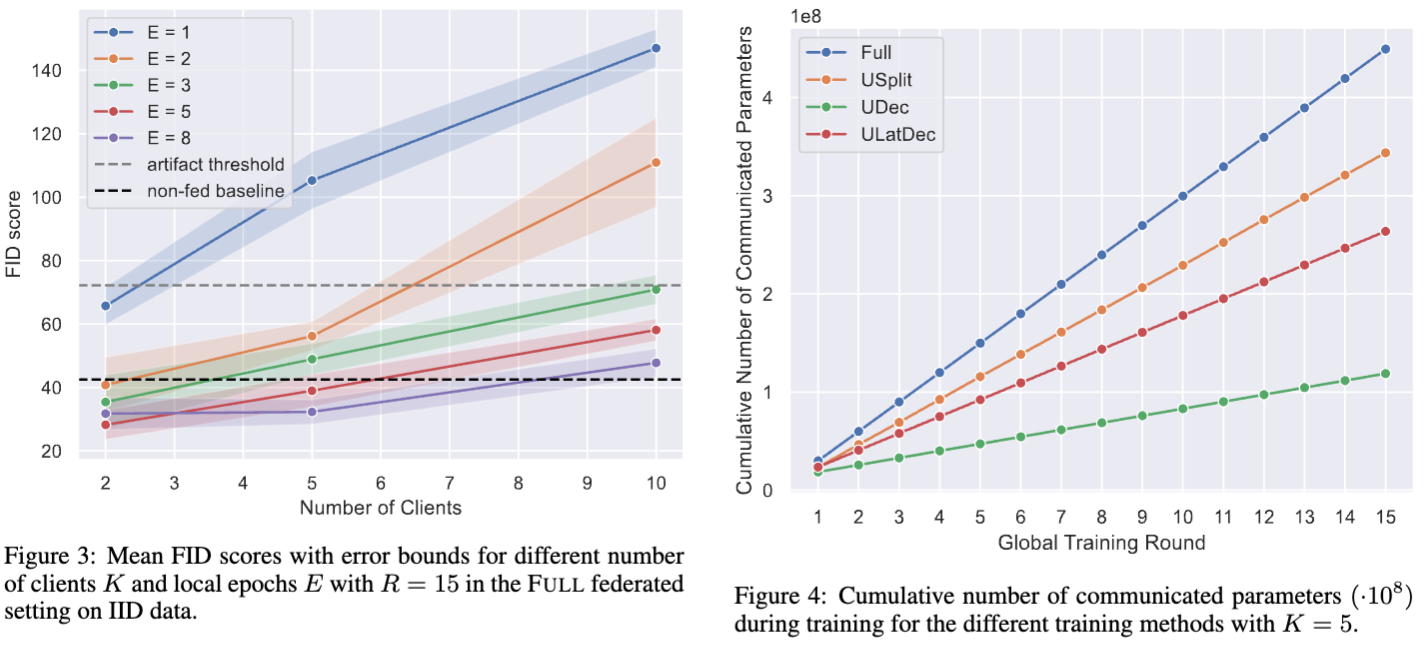
Experimental Setup and Results
Although the FID score of FULL is the best, other methods may have their unique advantages in different scenarios, especially in terms of communication efficiency and resource management.
Experimental Setup and Results
The quality of generated images is evaluated using the FID score, demonstrating the model’s ability to learn effectively in IID settings.
In non-IID settings, model performance is adversely affected, especially as the number of clients increases, leading to challenges in learning all class features.
The research highlights the significant impact of data distribution on training methods, showcasing high-quality image generation by the FedDiffuse model in IID conditions.
